
This a retrieved form of the original article from the series, ‘A Spotlight on Undergraduate Research’.
Edited by Niharika Gunturu.
The author is extremely lazy and hence wants to teach a machine to do all of his work.
Rahul Ramesh, a 5th-year Dual Degree student from the Department of Computer Science and Engineering, gives us a glimpse into his Dual Degree Project – which revolves around building hierarchies for reinforcement learning agents, or a reusable collection of skills that can help agents solve sequential decision making tasks.
Artificial intelligence (AI) was conceptualized long before computers became ubiquitous household objects. A defining moment of the past is Turing’s landmark paper on computing and its relation to intelligence. This paper is the genesis of the popular Turing test that attempts to formalize the notion of machine intelligence.
The test states that a machine is said to exhibit intelligent behaviour if it is indistinguishable to a human. While the definition is far from complete (and heavily debated), it provides us with a much needed operational starting point. An agent capable of passing the Turing test would hence require the following modules:
- Perception: Vision, natural language processing and speech recognition
- Learning: Build representations and models of the world
- Decision: Planning, Communication and acting in the world
Progress in AI has spawned an interest in numerous areas like Computer Vision, Natural Language Processing and Deep Learning. Reinforcement Learning (RL) is one such area.
RL concerns itself with sequential decision-making problems. At its core, RL employs a trial-and-error paradigm to identify the optimal behaviour. In a typical RL setup, the agent ‘learns’ a behaviour policy guided by a scalar signal known as ‘the reward’. Unlike the popular supervised learning setup in machine learning, the agent is not spoon-fed with an optimal sequence of actions and is left to infer the same, solely from the rewards. This often results in interesting and non-intuitive solutions to problems, that typically evade the human mind.
The difficulty arises from the fact that a reward received at the current step could be attributed to a crucial decision or action taken a 100 or 1000 steps earlier! This is formally known as the ‘temporal credit assignment problem’ and the concerned algorithms have to account for the effect that decisions have – far into the future.
The RL formally models the environment as a Markov Decision Process, which consists of states, actions, a transition function and a reward function.
 Consider a game like Super Mario Bros where the aim, is to achieve as high a score as possible. This entails making a precise sequence of decisions. Here, the current state is the visual input – based on which an agent determines an appropriate action – which are the various possible button combinations. As a result, an appropriate reward is then presented by the game alongside the consequent visual input (which is determined by the transition function). The agent is trained to maximize the cumulative sum of rewards acquired over the course of a single gameplay. Hence the algorithm must learn to navigate to promising states and must be willing to make short-term sacrifices, to reap long-term benefits (for instance: sacrificing a chess piece at present to win the game after a few moves).
Consider a game like Super Mario Bros where the aim, is to achieve as high a score as possible. This entails making a precise sequence of decisions. Here, the current state is the visual input – based on which an agent determines an appropriate action – which are the various possible button combinations. As a result, an appropriate reward is then presented by the game alongside the consequent visual input (which is determined by the transition function). The agent is trained to maximize the cumulative sum of rewards acquired over the course of a single gameplay. Hence the algorithm must learn to navigate to promising states and must be willing to make short-term sacrifices, to reap long-term benefits (for instance: sacrificing a chess piece at present to win the game after a few moves).
Video games naturally fall into the framework of Markov Decision Processes and have hence served as popular test beds for testing out new Reinforcement Learning algorithms. The world’s best chess and Go players are RL agents and both use the exact same learning algorithm. These agents learn by playing against themselves and use no human knowledge to develop strategies! The game of Go is particularly challenging due to the sheer number of possible moves. Earlier, it was thought that the field would require at least 10 more years before it could be solved satisfactorily. Open AI has the world’s best 1v1 player and an extremely competitive 5v5 bot in the infinitely complex game of DoTA. The interest in RL was ignited by breakthrough performances on the Atari-2600 domain, where Deepmind demonstrated that a single RL algorithm can achieve near-human or super-human performances across 56 tasks! While a number of factors made this work feasible, a principle driving force was the advent of deep-learning.

Left: Learning dexterous manipulation using a robot (Image source :https://blog.openai.com/learning-dexterity/)
Right: Learning to walk with a humanoid by controlling muscle activation. (AI for Prosthetics challenge https://www.crowdai.org/challenges/nips-2018-ai-for-prosthetics-challenge )
Traditionally, RL agents have struggled to produce competitive performances on problems with a prohibitively large number of states (for example, any problem with image inputs). As a consequence, problems that used large vectors, or complex visual inputs were initially infeasible to tackle. Therefore, there was a dire need for mathematical tools that help agents generalize across multiple states.
For example, every new game of Go is different from all previously played games and brute force memorization does not suffice.
The resurgence of Deep Learning provided a mechanism to build representations that generalize across states, allowing an agent to contextualize a previously unseen input, in terms of the other similar ones. Neural Networks (the model used in Deep Learning) are a result of a crude attempt to model the brain. The networks are initialized with random weights, which are modified to become stronger or weaker, based on input data fed to it – so that it is able to derive patterns out of the provided data. The neural net can consequently be utilized to operate on inputs that are similar (but not identical) to the data that it had seen earlier.
Aided by Deep Learning, RL algorithms have managed to scale to larger problems and address a myriad of tasks. The generality of Deep Learning, coupled with the success of RL has led to an active interest in ‘Deep-Reinforcement Learning’ based approaches as a means to address a plethora of problems, which include autonomous driving, robotic manipulation, advertisement delivery and financial trading.
Training an RL agent typically involves exploring the environment followed by exploiting the knowledge acquired from the same. The agent initially has no knowledge of the environment and behaves in an arbitrary fashion. Consequently, it gradually alters its behaviour to optimize for the reward signal, until it converges upon the optimal solution to the problem.
However, trial-and-error based solutions are prohibitively slow primarily because the agent is imbibed with no knowledge of the world. For instance, consider a robot that is learning to throw a ball. Apart from learning the technique, the robot must also learn that gravity exists! Most algorithms do not provide the agent with a set of facts (like the physics of the world), which humans often use to solve new tasks.
One possible solution is to build or provide the agent, with a model of the world or enforce the agent to explicitly learn the same. This area is termed as model-based learning in RL. Another popular approach, is to use the knowledge of solutions to similar problems in order to learn a new task rapidly. This area of research is called transfer learning, and is an important source of bias to the agent.
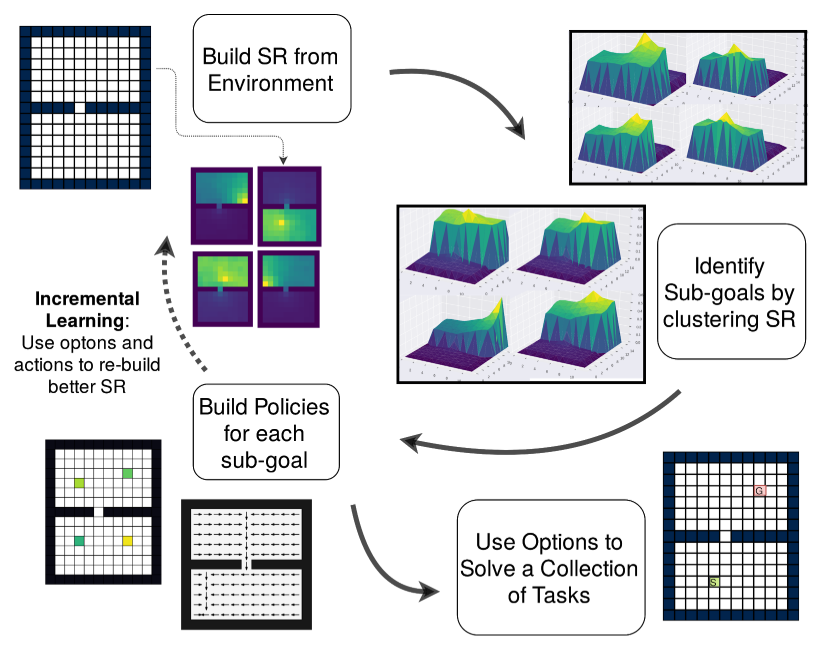
Another orthogonal approach and an area of interest to me, is the role of hierarchies in RL. Hierarchical RL internally structures the agent into multiple levels of abstraction which operate on simplified state or action spaces. To elucidate this idea, let us consider a task where an agent needs to navigate from one building to another. Instead of operating with primitive actions ( like “move 1 meter to the left”, “move 1 meter to the right”, etc…), it is instead beneficial to operate with a set skills (sequence of actions) like, “exit the room” or “go to the first floor”. A temporally extended sequence of actions (or a skill) has been formalized in RL through the options framework. An ideal option could be re-usable across multiple tasks or could otherwise accelerate the learning on one particular task. One can also understand an option as a solution to a sub-problem (exiting the room is a sub-problem for navigating to a different building). Furthermore, It is evident that one could breakdown every sub-problem into even smaller fragments, thereby leading to multiple layers in the hierarchy. Hence, the controller at the highest level sets out to solve a particular task which can be achieved by a composition of actions or smaller sub-tasks.
Using these pre-learnt set of skills, the learning process is hastened, since the agent can navigate to important and relevant states rapidly. However, discovering a set of task-agnostic options is a traditionally hard task and the proposed solutions in literature often involve heuristics, in one form or another. The most popularly used heuristic is to identify bottleneck states (like a doorway in a navigation task) and build options that navigate to these selected bottlenecks. This can lead to interesting behaviours like picking up objects in environments or navigating to states from which crucial decisions are made. Common environments, for sanity checking new frameworks are grid-worlds, where the agent (in red) is required to navigate to an assigned goal. The agent is allowed to move in any of the 4 directions and receives a reward of +1 on reaching a pre-defined goal.

Left: A sample grid-world task where the agent (in red), can move to any adjacent cell in the grid at every time step.
Center: The Successor representation vector for a single state, projected onto the grid world.
Right: The coloured squares are sub-goals for the agent, and navigating to a sub-goal is defined to be one option (or skill). These are sub-goals discovered by our method Successor options.
While bottlenecks are valid sub-goals for constructing options, we are currently working on a complementary approach to the same which involves identifying “landmark” states. Landmarks are prototypical states of well-connected regions in state-space. In a grid-world, this would approximate to the middle of each room, with each room representing one well-connected region.
Hence, a slightly larger grid-world (like in the Figure above [left]) would have sub-goals as identified by the green states. These sub-goals are in fact discovered by the Successor options framework, proposed as a part of my dual degree project. This option discovery framework utilizes Successor representations proposed by Peter Dayan in 1993. These representations are inspired from a hypothesis in neuroscience that rats represent their current state in terms of where they will be in the future. Successor representations have interesting properties and implicitly encode the connectivity information of the states in the environment. The underlying idea behind this work is to identify a fixed set of sub-goals that have well separated Successor representations. This roughly translates to mean that navigating to any sub-goal, provides the agent access, to a different set of states consequently.
Successor representations also have a succinct formulation in the Deep learning setup which makes our proposed Successor options algorithm easily extendible to complex domains. We are capable of addressing environments like Deepmind Lab and Vizdoom, which are maze navigation domains with high dimensional RGB visual inputs. Hence the deep learning model is capable of localizing its position in the domain from the visual input, while also building interesting skills in an unsupervised fashion (Agent uses same method to build skills on different environments). In domains like Fetch (retrieving an object with a robotic arm) we discover skills that perform different manipulations of the robotic arm, leading the agent to different useful configurations.

Left: Deepmind Lab maze navigation task and Right: The Fetch-Pick and Place (robotic manipulation) task
As future work, we plan on developing an end-to-end training procedure. of the arm. However, we realize that this technique, like its predecessors, is far from being a one size fits all option discovery technique. Automated skill learning continues to remain an open problem and addressing the same, can help construct robust hierarchies. This is an important next step, if RL agents aim to scale to more complex tasks. At the same time, there are a number of other vertical in RL that call for similar progress. Amidst the immensely promising results, Reinforcement learning is still plagued by issues pertaining to its data hungry nature, which can be mitigated by progress in exploration, transfer and model-based RL. It is for precisely this reason, that the area has attracted considerable interest, and the field currently finds itself at a fascinating juncture.
Rahul Ramesh is a 5th-year Dual Degree student from the Department of Computer Science and Engineering. This article describes the work done as a part of his dual degree project under the guidance of Prof. Balaraman Ravindran, in collaboration with Manan Tomar.


